Overview
| RAG Technique | Simple Definition | When to Use |
|---|---|---|
| Simple RAG | Retrieves relevant documents based on the query and uses them to generate an answer | Basic question-answering tasks where context is needed |
| Simple RAG with Memory | Extends Simple RAG by maintaining context from previous interactions | Conversational AI where continuity between queries is important |
| Branched RAG | Performs multiple retrieval steps, refining the search based on intermediate results | Complex queries requiring multi-step reasoning or information synthesis |
| HyDE (Hypothetical Document Embedding) | Generates a hypothetical ideal document before retrieval to improve search relevance | When dealing with queries that might not have exact matches in the knowledge base |
| Adaptive RAG | Dynamically adjusts retrieval and generation strategies based on the query type or difficulty | Varied query types or when dealing with a diverse knowledge base |
| Corrective RAG (CRAG) | Iteratively refines generated responses by fact-checking against retrieved information | High-stakes scenarios requiring increased accuracy and fact verification |
| Self-RAG | The model critiques and improves its own responses using self-reflection and retrieval | Tasks requiring high accuracy and when there’s time for multiple refinement steps |
| Agentic RAG | Combines RAG with agentic behavior, allowing for more complex, multi-step problem-solving | Complex tasks requiring planning, decision-making, and external tool use |
GitHub Link
Skills picked up
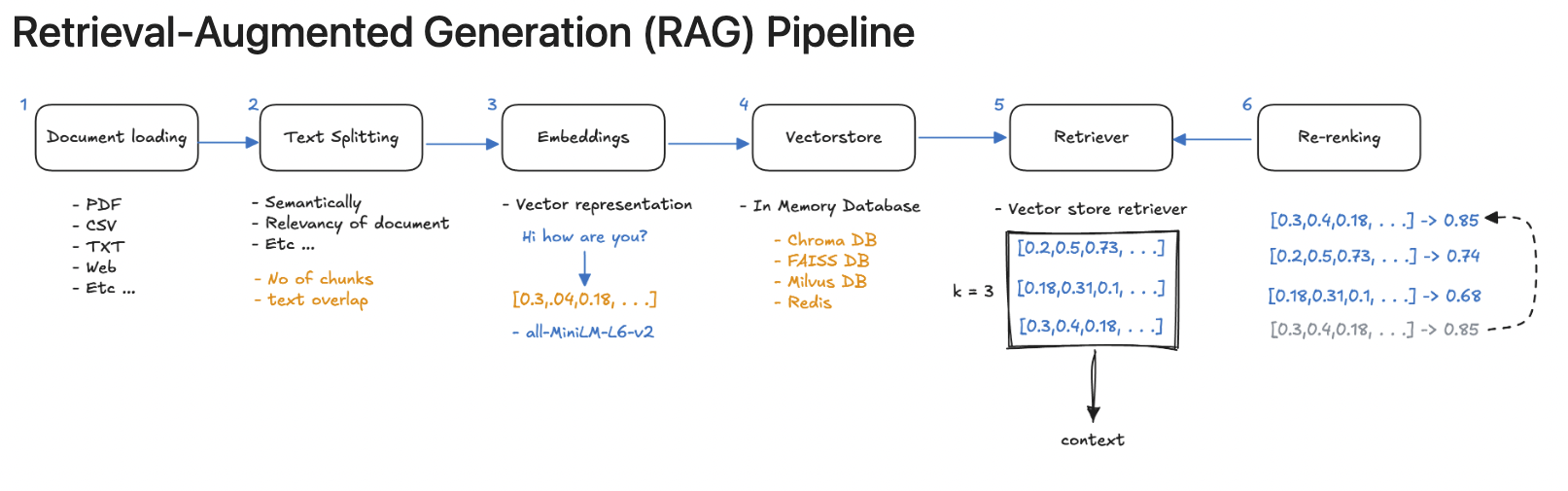
- Embeddings
- Sentence Transformer
- Vector stores
- Branched RAG