About
This code pattern showcases how to build an end-to-end AI-powered application that extracts summaries and insights from audio or video content using IBM Watson and open-source NLP models. It focuses on simplifying content consumption from unstructured multimedia data.Overview
The solution enables users to upload audio or video files and receive accurate transcripts, speaker diarization, summaries, and insights. Using IBM Watson Speech to Text, the audio is transcribed with improved readability through model tuning. The transcribed content is then processed using transformer and machine learning models (e.g., GPT-2, XLNet, Gensim) to generate summaries and keyword-based insights. The results are presented through an intuitive web interface, which can be deployed on local machines, IBM Cloud, or OpenShift.Architecture
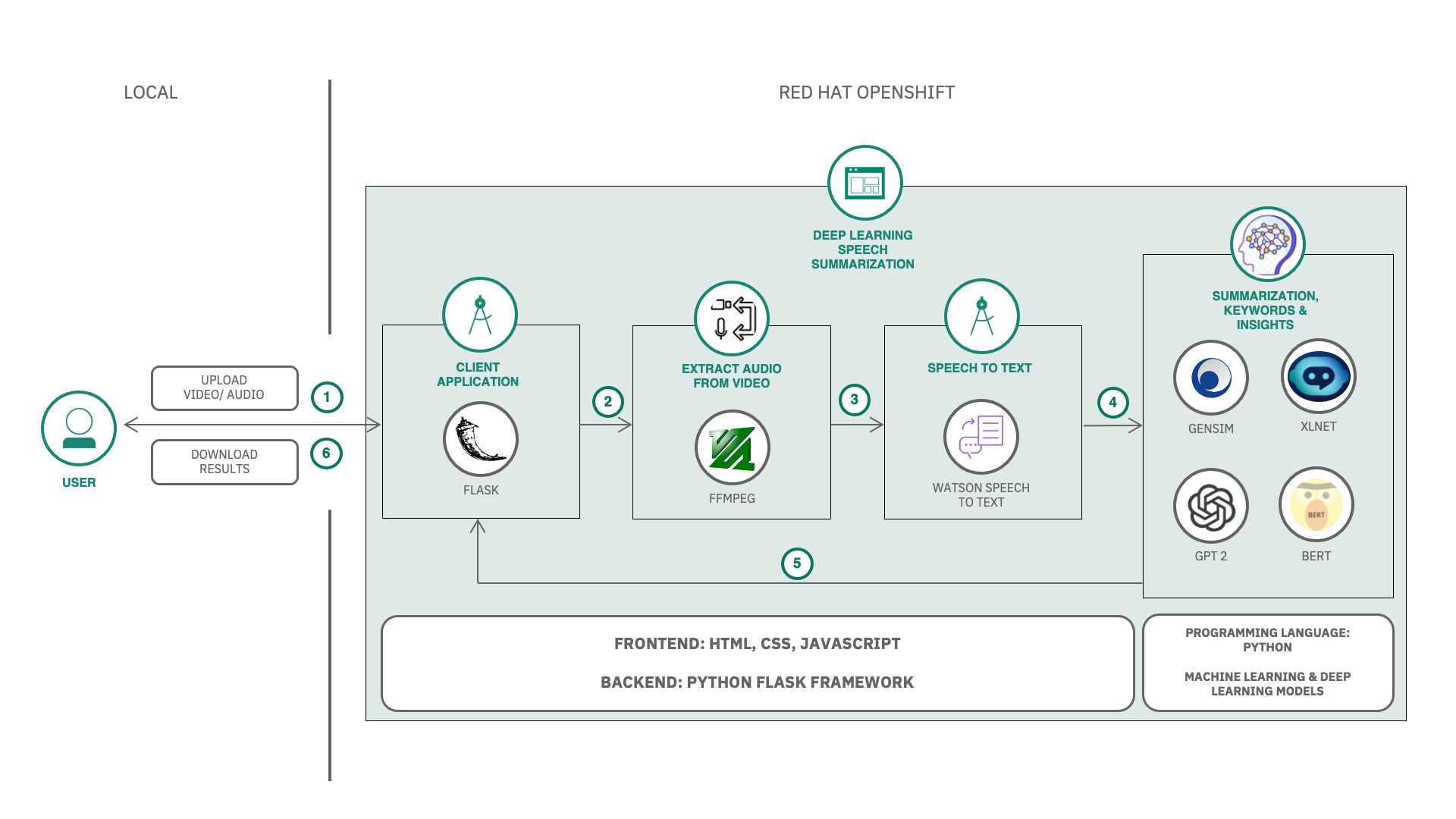
Solution
- Audio/Video Processing: Extracts audio from video and segments it for better handling.
- Speech-to-Text: IBM Watson Speech to Text is used to transcribe the content, with options for speaker labeling, smart formatting, redaction, and more.
- Summarization and Insights: Uses transformer-based (GPT-2, XLNet) and ML-based (Gensim, KeyBert) models to summarize and extract key insights.
- Visualization: Transcripts, summaries, speaker insights, and keywords are displayed on a web GUI.
- Deployment Options: Can be run locally using Docker or deployed on IBM Cloud or OpenShift.
Demo Link
GitHub Link
Skills Picked Up
- End-to-end application development using Python Flask
- Audio processing and video-to-audio conversion
- Integration and tuning of IBM Watson Speech to Text API
- Custom model training (language/acoustic models)
- Transformer-based models (GPT-2, XLNet via HuggingFace)
- Machine learning methods (Gensim TextRank)
- NLP techniques for keyword extraction (KeyBERT)
- Dockerization and deployment on cloud platforms (IBM Cloud, OpenShift)
- Visualization and web UI development for NLP outputs